還記得我們在 Day 24 的時候提到應用大型語言模型的四種方式嗎?
今天,我想要通過 Langchain 來實作看看,如何用最簡單的方式來對 LLM 下提示 ( Prompt ),讓它生成我們所想要的內容。
Langchain 是一個用於開發 LLM 相關應用的框架,如同它的名字一樣,Langchain 提供了很多的 modules 用在解決不同的任務上,並且將他們像一條鍊子一樣全部串連起來,也因此在推出的時候受到蠻多使用者的歡迎。
然而 Langchain 也因為一些問題而導致使用上的不便,比方說它的框架設計讓使用者無法接觸或編寫較為底層的程式碼,只能從表面去調用大型語言模型,因此最近也出現了更多 LLM 應用相關的框架,目前聽到最多的應該是 LlammaIndex。
不過對於新手使用者而言,我覺得 Langchain 還算是好上手,在網路上查資料的時候也有發現,無論是去年或今年都有好多大神在寫相關的介紹文章,讓我收穫非常多。
那麼,就讓我們開始實作吧!
首先,一如既往地打開 Colab,下載這次實作需要的函式庫:
!pip install langchain
!pip install langchain-openai
!pip install langchain-community
接著設定自己的 API key,這樣才能才用大型語言模型:
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY"
然後設定你想要使用哪一種模型和其它參數,就可以生成回應了:
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0)
llm.invoke("Give me a short sentence.")
AIMessage(content='The sun is shining brightly.', response_metadata={'token_usage': {'completion_tokens': 6, 'prompt_tokens': 13, 'total_tokens': 19}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='-')
AIMessage 中包含了 LLM 生成的回應以及相關的訊息,比方說我們用的是哪一個模型或使用的 token 數量情況。
此外,這裡要介紹一下 temperature 這個參數,它的作用是調控模型輸出回應的隨機性,如果溫度越高,那麼它就有更高的機會輸出帶有隨機性的回應,也就是更有創意的回答,反之則會傾向於輸出更穩定的回答。
接著要來介紹如何利用提示讓 LLM 按照我們想要的方向生成回應。
相信用過 ChatGPT 的人對提示 ( Prompt ) 多少都有些了解,它的作用就是對 LLM 下達清晰明確的指令,讓它能夠正確理解我們想要做的事情並執行。如果想要朝著詠唱師之路邁進,我們就必須先學會提示工程 ( Prompt Engineering )。
怎麼樣才算是一個好的提示呢?比方說我們可以在提出問題之前先給它一些樣本提示,讓它可以參考範例的做法或格式進行輸出。
以 One-Shot Prompting 為例,事先給一個例子讓 LLM 知道任務的具體內容,並根據使用者新的問題做出回應,我們來看看實際效果如何:
from langchain.prompts import PromptTemplate
template = """
Please translate this sentence from English to Chinese. Here is an example:
English: I like watching movies.
Chinese: 我喜歡看電影。
English: {query}
Chinese: """
prompt = PromptTemplate(
input_variables = ["query"],
template = template
)
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0.9)
chain = LLMChain(llm = llm, prompt = prompt)
response = chain.run({'query':'She is a nice person.'})
print(response)
她是一個好人。
我使用了 PromptTemplate 的格式,把使用者提出的問題當作參數放進去,此外,在這段程式碼中,我給了它一個明確的任務目標,並提供一個從英文翻成中文的例子,而 LLM 也確實只輸出翻譯結果,沒有產生像 以下是翻譯的句子 之類冗餘的回答。
此外,我也試了它提供的 LCEL (LangChain Expression Language) 的寫法:
import openai
from langchain.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
prompt = ChatPromptTemplate.from_template(
"""
Please translate this sentence from English to Chinese. Here is an example:
English: I like watching movies.
Chinese: 我喜歡看電影。
English: {query}
Chinese: """
)
output_parser = StrOutputParser()
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0.9)
chain = (
{"query": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
chain.invoke("She is a nice person.")
這個做法更能展現出一個一個部件串接在一起的感覺,此外,使用 StrOutputParser 可以直接輸出 她是一個好人。 的字串。
另外一個對推理任務來說很有效的方式叫做思維鏈 ( Chain-of-Thought, CoT ),在 2022 年的論文《 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 》中用這張圖來說明它是怎麼下 prompt 的: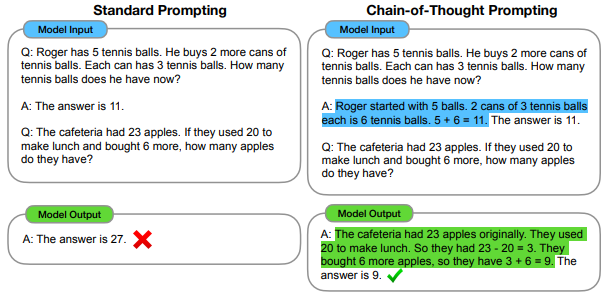
根據這篇論文的介紹,在原本的輸出中,即便我們使用 One-Shot 的方式,模型還是輸出錯誤,然而當我們給出了詳細的解題方式,模型竟然就能按照相同的思路做出正確的推理了。
由此可知,當我們給出越多資訊,讓 LLM 越了解我們的意圖,它就越能輸出正確且符合我們期待的結果。
而這幾年隨著 LLM 快速發展,幾乎是每幾個月就蹦出新的功能強大的模型,關於提示工程的相關研究也不斷在進化,我找到的這一篇論文《 A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications 》就是在調查這幾年所提出的各種 Prompting 技術,大家有興趣可以去看看。
今天的實作老實說並沒有觸及到 Langchain 比較 powerful 的應用,像是 Agent 或是 Memory,不過我想之後如果有機會應該會想嘗試學學看其它同樣可以開發 LLM 相關應用的框架,這也是我的學習目標之一。
明天會聊聊另一個也很常用的技術:檢索增強生成 ( Retrieval-Augmented Generation, RAG ),然後就準備來收尾啦!
推薦文章
PS : 推薦生成式 AI 組這位大大的系列文:LLM 應用、開發框架、RAG優化及評估方法

